Why First-Party Data is the Engine Behind Agentic Personalization

Updated on 16 Jun 2026
10 min.
Table of Contents
- Summary
- Why agentic AI breaks without a strong first-party data foundation
- The four data layers every agentic personalization stack requires
- Zero-party vs. first-party data: how agents use each signal type
- Consent and data governance as agentic performance infrastructure
- First-party data readiness: a five-question audit before you deploy agents
- Identity resolution and signal freshness
- Is your identity resolution complete enough to support real-time decisioning?
- How fresh are your behavioral signals at the point of agent decisioning?
- Consent, cross-channel visibility, and auditability
- What percentage of your active customer profiles carry valid, current consent records?
- Do agents have visibility across every channel where customers interact?
- Can you audit any individual agent decision after the fact?
- FAQs
Most Popular


Summary
AI agents depend on accurate, real-time customer data, poor or fragmented data can scale bad decisions quickly. Effective agentic personalization requires unified profiles, live behavioral signals, consent governance, and cross-channel identity data, while combining zero-party and first-party data improves decision quality. Insider One connects its CDP and AI agents on the same real-time data layer, enabling faster, more reliable personalization without external data transfers.
Over the past two years, marketing teams have spent a lot of time asking whether their tech stack is ready for AI. The more urgent question is whether their data is. An AI agent that can autonomously trigger offers, suppress messages, and reroute customer journeys across channels is only as good as the signals it reads. Plug it into fragmented, poorly governed data, and it doesn’t merely underperform: it confidently misfires at scale.
The vendor pitch for agentic systems typically focuses on agent orchestration, channel reach, and decisioning speed. What it often omits is the data-layer architecture that makes autonomous decisions legally defensible, contextually accurate, and genuinely trustworthy. That architecture starts with first-party data, and it requires a discipline that goes well beyond collection.
Why agentic AI breaks without a strong first-party data foundation
For low-complexity, predictable scenarios, rule-based automation remains entirely appropriate and effective. When a segmentation condition is wrong or a trigger fires at the wrong moment, the impact is bounded: one bad email, one missed push notification, and a human can intervene before the error compounds.
Agentic personalization operates differently. An AI agent running autonomously across millions of customer interactions compounds every data error it encounters, and a stale identity graph doesn’t produce a single misfire: it produces a repeating pattern of misfires that the agent reinforces through continued decision-making.

From batch pipelines to real-time signal dependency
Traditional marketing automation was designed around batch data pipelines. You export a segment, build a campaign, and schedule a send. The data is never truly live, but the system tolerates latency because human decisions buffer every step.
Agents don’t have that buffer: they read signals, form judgments, and act, often within seconds of a behavioral event. A customer abandoning a cart, downgrading a subscription, or browsing a product category for the third time in a week represents a live signal that an agent is built to act on immediately.
When that signal sits in a siloed customer relationship management (CRM) platform that refreshes overnight, or lives in an ad platform that doesn’t communicate with the web analytics layer, the agent is effectively personalizing blind. It isn’t working with an incomplete picture of a person who may have already converted, churned, or changed intent: it’s working with yesterday’s picture entirely.
The four data layers every agentic personalization stack requires
Think of these layers as load-bearing. Remove any one of them and the structure doesn’t just weaken: it creates specific, predictable failure modes.
Unified real-time customer profiles with identity resolution
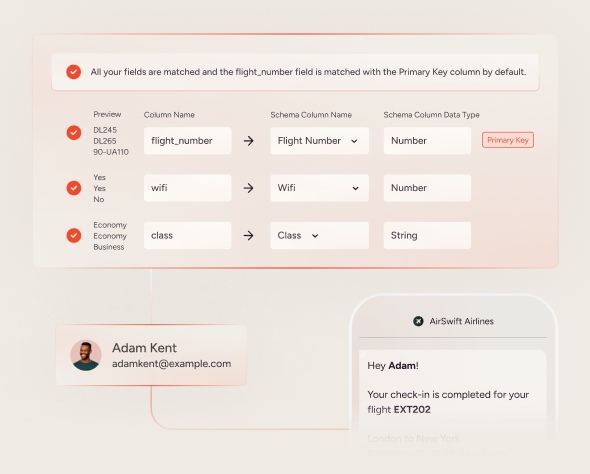
A unified profile is a continuously reconciled view of a person across every touchpoint they’ve ever used: anonymous web sessions, logged-in mobile behavior, email engagement, in-store purchases, and support interactions. Identity resolution, the process of matching fragmented signals back to a single profile, is the foundation of this layer. Without it, an agent may target the same person multiple times across different channels because it sees several different identities, producing an incoherent customer experience and wasted spend.
Streaming behavioral signals
Static profiles describe who someone was. Streaming behavioral signals describe what they’re doing right now. Agents depend on event-stream data, including page views, search queries, product interactions, and session depth, to make decisions that are contextually relevant to the present moment.
A first-party data strategy that only captures transactional history gives agents a rearview mirror when they need a live feed.
Governed consent management
Every signal an agent uses to make a decision must be permissioned. This isn’t a regulatory footnote: it’s a structural requirement. If an agent draws on a behavioral signal that the user never consented to share for personalization purposes, any decision derived from that signal is legally exposed. Governed consent management means knowing, for every data point in the profile, what the user agreed to, when they agreed to it, and whether that consent is still valid.
A cross-channel data view that eliminates blind spots
Most enterprise brands have channel-specific data silos: email metrics in one platform, push data in another, and paid media attribution in a third. An agent operating without a unified cross-channel view will optimize within whatever slice of reality it can see. It might correctly identify that a customer hasn’t responded to email in 30 days, but without visibility into the fact that they’ve been highly active in the mobile app, it could trigger a lapsed-user re-engagement campaign at exactly the wrong moment.
Adidas achieved a 259% increase in average order value and a 13% lift in conversion rate in one month by working from a unified cross-channel view that allowed personalization to respond to the whole customer, not a channel-specific fragment.

Zero-party vs. first-party data: how agents use each signal type
The terms are often used interchangeably, which creates real strategic confusion. They are not the same thing, and agents don’t treat them the same way.
Defining the practical difference
Zero-party data is what a customer deliberately shares: quiz answers, preference center selections, stated product interests, and self-declared purchase intent. It’s explicit, structured, and carries the highest confidence weight because no inference is involved. The person told you directly.
First-party data is behavioral and transactional: what pages someone visited, what they purchased, how long they engaged with a campaign, and what they clicked but didn’t buy. It’s richer in volume, but it requires interpretation, and interpretation introduces probabilistic reasoning that can be wrong.
Understanding the relationship between first-party data and cookie-based targeting also matters here. Third-party data adds surface-level demographic breadth but lacks the causal specificity that agents need to make high-confidence decisions. It tells you a customer might be interested in outdoor gear.
First-party behavioral data tells you they’ve viewed the same hiking boot twice in five days and added it to a wishlist. Those are not equivalent signals.
Why combining both creates a more reliable decisioning model
Agents that operate on behavioral data alone are working from probabilistic inference without anchoring signals. Zero-party data acts as a confidence layer: it confirms or contradicts what behavioral patterns suggest, reducing the risk of model-driven errors in high-stakes moments.
A customer whose behavioral signals suggest price sensitivity, but who has explicitly stated in a preference center that they prioritize sustainability over cost, should be routed differently. An agent with access to both signal types gets that right, while one relying only on behavioral data may not.
This combined identity graph also addresses one of the practical risks of agentic systems: over-personalization that feels intrusive. When agents have explicit preference signals alongside behavioral data, they can personalize with more precision and less guesswork.
Consent and data governance as agentic performance infrastructure
Reframe how your team thinks about consent management. It isn’t exclusively the legal team’s responsibility: it is the infrastructure that determines what your agents are permitted to do autonomously. When consent and data lineage are properly structured, an agent can operate with genuine autonomy because it knows which signals are in bounds and which are not.
Without that structure, autonomous agents either over-restrict, defaulting to the safest possible action because they can’t verify permissions, or under-restrict, acting on signals that aren’t properly permissioned and creating compliance exposure. Neither outcome serves the business.
Data lineage, meaning knowing where every data point came from, how it was collected, and what transformations it went through, matters for a separate reason: when an agent makes a decision that produces an unexpected outcome, lineage tracking is what lets your team audit the decision and understand why it happened. Without it, agentic systems become black boxes that are difficult to debug, improve, or defend.
The governance primitives teams must build before scaling
Before scaling any agentic personalization system, four governance primitives must be in place:
• Access controls: define which agents can read which data categories, and enforce those controls programmatically
• Data quality rules: establish minimum freshness thresholds and completeness standards that signal data must meet before agents are permitted to act on it
• Lineage tracking: log the origin, transformation history, and consent status of every signal in the decisioning path
• Bounded autonomy guardrails: set explicit limits on what categories of decisions agents can make without human review, particularly for high-value or high-sensitivity interactions such as pricing, churn intervention, or loyalty tier changes
This is the architecture that makes AI-driven personalization defensible, not just functional. Insider One’s AI overview covers how Sirius AI™ and Agent One™ are built on this kind of governed decisioning approach, where autonomous actions are bounded by auditable rules rather than unrestricted inference.
First-party data readiness: a five-question audit before you deploy agents
Before you hand decision-making authority to an agent, you need an honest assessment of whether your data infrastructure can support it. The questions below cover the two most common structural gaps: identity and signal quality, then governance and cross-channel visibility.
Identity resolution and signal freshness
Is your identity resolution complete enough to support real-time decisioning?
If your customer data platform (CDP) cannot resolve anonymous and known identities within a single session, agents will routinely personalize for the wrong person or miss behavioral context entirely. The gap to close is investing in both probabilistic and deterministic matching before enabling agent-driven targeting.
How fresh are your behavioral signals at the point of agent decisioning?
If the answer is “refreshed daily” or “refreshed hourly,” that cadence is not compatible with real-time agentic personalization. The gap to close is moving toward event-stream ingestion so agents read signals that reflect what’s happening now, not what happened last night.
Consent, cross-channel visibility, and auditability
What percentage of your active customer profiles carry valid, current consent records?
If consent records are incomplete, segmented, or stored separately from the profiles agents read, you have a governance gap that directly limits agent autonomy. The gap to close is consolidating consent data into the unified profile layer and building consent-check logic into every agent decisioning path.
Do agents have visibility across every channel where customers interact?
If your mobile app data, email engagement data, and web behavioral data live in separate platforms without a unified view, agents are operating on partial context. The gap to close is building or configuring a cross-channel data view before expanding agent scope beyond a single channel. Insider One’s journey orchestration layer is designed precisely for this kind of cross-channel decisioning problem.
Can you audit any individual agent decision after the fact?
If you cannot reconstruct why a specific offer was shown to a specific customer at a specific moment, your lineage tracking is insufficient for enterprise-grade agentic deployment. The gap to close is implementing decision logging at the agent level, tied to the specific data inputs and consent state at the time of the decision.
For teams working through this audit, Insider One’s Customer Data Management layer is built to address each of these readiness gaps directly, so that first-party data doesn’t just feed agents: it governs them.
Slazenger’s experience illustrates what structured data readiness unlocks: 49x return on investment (ROI) in 8 weeks, achieved because the data infrastructure could support fast, confident, cross-channel decisioning without requiring constant human intervention at each touchpoint.
If you’re evaluating how to build or strengthen the data foundation your agentic personalization program needs, explore how Insider One’s platform connects Customer Data Management, governed consent, and cross-channel decisioning into a unified architecture.
Request a personalized demo to see Agent One™ and Sirius AI™ operating on your own data layer, so you can assess exactly which decisioning guardrails and identity resolution capabilities apply to your stack.
FAQs
Zero-party data is explicitly shared by the customer, including preference center choices, quiz responses, and stated interests. First-party data is observed behavioral and transactional data collected through your own channels. In agentic systems, zero-party data acts as a high-confidence anchor that reduces the inferential risk inherent in behavioral signal interpretation. A customer data platform (CDP) that unifies both signal types gives agents a more reliable foundation for autonomous decisions.
Start with identity resolution. If your system cannot reliably match anonymous and known user behavior to a single profile, every downstream layer, including consent records, behavioral signals, and cross-channel visibility, will produce errors that compound at agent speed. Resolve identity first, then audit signal freshness and consent coverage before expanding agent scope.
Use the five-question readiness audit in this article as a starting point. The most common blockers are incomplete identity resolution, batch-refresh data pipelines that can’t support real-time decisioning, and consent records that aren’t integrated into unified customer profiles. Addressing those three gaps before expanding agent scope will prevent the most costly failure modes.
Agents can only make confident autonomous decisions when they know which signals are permissioned and verified. Incomplete governance forces agents into either over-cautious default behavior or legally exposed decisions. Proper data lineage, access controls, and consent management are what allow AI agents to operate at speed without requiring human review of every action.

Keep Reading
7 min.
Muharrem Derinkok
4 Jun 2026
11 min.
Chris Baldwin
2 Jun 2026
4 min.
Chris Baldwin
3 Feb 2026