La puissance de l’hyperpersonnalisation dans le Retail : les avantages clés

Mise à jour le 21 Avr 2026
25 min.
Table des matières
- Qu'est-ce que l'hyperpersonnalisation dans le retail ?
- Pourquoi l'hyperpersonnalisation est-elle importante pour les retailers ?
- Quels sont les éléments clés d'une pile d'hyperpersonnalisation pour le retail ?
- Quels sont les cas d'usage de l'hyperpersonnalisation au retail qui comptent dans le parcours client ?
- Comment fonctionnent la recherche personnalisée et la découverte de produits ?
- Comment fonctionnent les modules dynamiques de pages d'accueil et de catégories ?
- Comment gérer les abandons de panier et de navigation avec des offres tenant compte des stocks ?
- Comment fonctionnent le clientélisme en magasin et les recommandations assistées par les associés ?
- Comment fonctionnent les programmes de réapprovisionnement, de reconquête et de fidélisation après achat ?
- Quelles sont les exigences en matière de données et d'IA qui soutiennent l'hyperpersonnalisation sans surveillance ?
- Quelle est la feuille de route de l'hyper-personnalisation du retail ?
- Comment Insider One favorise-t-il l'hyperpersonnalisation du retail ?
- FAQ
Les plus populaires

Principaux enseignements
L’hyperpersonnalisation dans le retail signifie prendre des décisions d’expérience pour chaque acheteur individuel en temps réel, en utilisant des signaux comportementaux en direct et des contraintes commerciales telles que l’inventaire et la marge.
- Elle diffère de la segmentation en décidant par personne, par moment, et non par groupe d’audience
- Vous avez besoin de composants clés qui fonctionnent ensemble : données unifiées, résolution des problèmes d’identité, prise de décision en temps réel, activation omnicanale et mesure.
- Les équipes peuvent lancer un premier cas d’usage avec des résultats mesurables en l’espace d’un trimestre.
Aujourd’hui, la plupart des retailers pratiquent une « personnalisation » qui est encore basée sur des segments. De nombreux acheteurs voient la même bannière parce qu’ils partagent des caractéristiques démographiques ou qu’ils ont parcouru la même catégorie la semaine dernière. L’hyperpersonnalisation dans le retail fonctionne différemment. Elle prend des décisions au niveau individuel, en temps réel, en utilisant des signaux comportementaux, des données contextuelles telles que l’appareil et la localisation, et des contraintes commerciales telles que le stock et la marge.
Ce guide explique ce qu’est l’hyperpersonnalisation, en quoi elle diffère de la segmentation, et comment construire une pile qui apporte une amélioration mesurable. Vous découvrirez les composants nécessaires, les cas d’usage les plus importants dans le parcours client et une feuille de route pour lancer votre premier cas d’usage avec une incrémentation prouvée.
Qu’est-ce que l’hyperpersonnalisation dans le retail ?
La plupart de la « personnalisation » dans le retail aujourd’hui est encore basée sur les segments. De nombreux acheteurs voient la même bannière parce qu’ils partagent des caractéristiques démographiques ou qu’ils ont navigué dans la même catégorie la semaine dernière. L’hyperpersonnalisation fonctionne différemment.
L’hyperpersonnalisation est la pratique qui consiste à prendre des décisions en matière d’expérience au niveau individuel, en temps réel, en utilisant des signaux comportementaux, des données contextuelles telles que l’appareil et l’emplacement, et des contraintes commerciales telles que le stock et la marge. La caractéristique déterminante est la prise de décision par demande, et non les listes d’audience préétablies.
Pensez-y comme à un spectre de maturité : le marketing de masse se situe à un extrême, puis la personnalisation par segment, puis la personnalisation individuelle qui s’actualise tous les jours ou toutes les heures, et enfin l’hyperpersonnalisation qui décide dans l’instant.
Si votre catalogue est petit, que le trafic est faible ou que la variance des marges entre les produits est négligeable, la personnalisation par segment permet d’obtenir des résultats similaires avec moins de complexité. L’hyperpersonnalisation mérite ses frais généraux lorsque vous avez l’échelle et la diversité des marges qui la justifient. Le BCG prévoit une opportunité de personnalisation de 2 000 milliards de dollars pour les entreprises qui parviennent à créer des expériences basées sur l’intelligence artificielle (IA).
En quoi l’hyperpersonnalisation diffère-t-elle de la segmentation et de la personnalisation individuelle ?
| Dimension | Basé sur le segment | Individuel (lot) | Hyper-personnalisation |
| Granularité | Cohorte d’audience | Individuel | Individuel |
| Calendrier | Préprogrammé | Rafraîchissement quotidien/horaire | Par demande |
| Entrées de données | Attributs historiques | Caractéristiques historiques et dérivées | Vivre les contraintes comportementales, contextuelles et commerciales |
| Traitement des contraintes | Aucun | Limitée | Inventaire, marge, plafonds de fréquence appliqués au moment de la décision |
| Exemple de déclencheur | « Niveau de fidélité = Or » | « A consulté la catégorie X récemment » | « Navigation dans les soldes sur mobile, faible stock, marge supérieure au seuil » |
L’hyperpersonnalisation nécessite une infrastructure capable d’ établir des scores et des classements en quelques millisecondes. Cela modifie les décisions de construction ou d’achat pour les équipes qui n’ont pas de capacité d’ingénierie en apprentissage automatique.
Pourquoi l’hyperpersonnalisation est-elle importante pour les retailers ?
Les retailers doivent composer avec des marges minces, des taux de retour élevés et une pression promotionnelle qui érode la rentabilité. La personnalisation générique augmente souvent la conversion au détriment de la marge, en escomptant des clients qui auraient payé le prix fort, ou crée une lassitude en envoyant trop de messages aux acheteurs à forte valeur ajoutée.
L’hyperpersonnalisation y remédie en prenant en compte les contraintes de l’entreprise dans chaque décision :
- Taux de conversion : Les décisions basées sur des signaux d’intention en direct, tels que la profondeur de défilement et le temps passé sur les pages produits, permettent de détecter les micro-moments de préparation à l’achat qui échappent aux segments statiques.
- Valeur moyenne des commandes : Les recommandations de cross-sell qui respectent les planchers de marge et les niveaux de stock évitent de promouvoir des articles qui nuisent à la rentabilité.
- Valeur de la durée de vie du client : Les décisions relatives à la fréquence et au canal qui tiennent compte de la fatigue réduisent les abandons et préservent la capacité d’engagement à long terme.
- Efficacité des stocks : L’identification en temps réel des stocks à rotation lente pour les acheteurs sensibles aux prix permet de réduire la profondeur des démarques en fin de saison.

Quels sont les éléments clés d’une pile d’hyperpersonnalisation pour le retail ?
Les équipes investissent souvent dans un moteur de recommandation ou une plateforme d’email en s’attendant à une hyperpersonnalisation. Mais en l’absence de données unifiées, de résolution d’identité et d’infrastructure de mesure, elles continuent d’exécuter des campagnes basées sur des segments avec une interface plus sophistiquée.
Un stack complet nécessite ces composants :
- Base de données de première partie : Le flux d’événements et les attributs du catalogue qui alimentent chaque décision en aval.
- Résolution d’identité : La logique qui permet de relier les profils anonymes et connus à travers les appareils et les canaux.
- Moteur de décision en temps réel : le système qui note, classe et applique les contraintes au moment de la demande.
- Activation omnicanale : Les adaptateurs de canaux qui offrent des expériences personnalisées de manière cohérente.
- Mesure et expérimentation : L’infrastructure d’attente et d’essai qui prouve l’incrémentalité
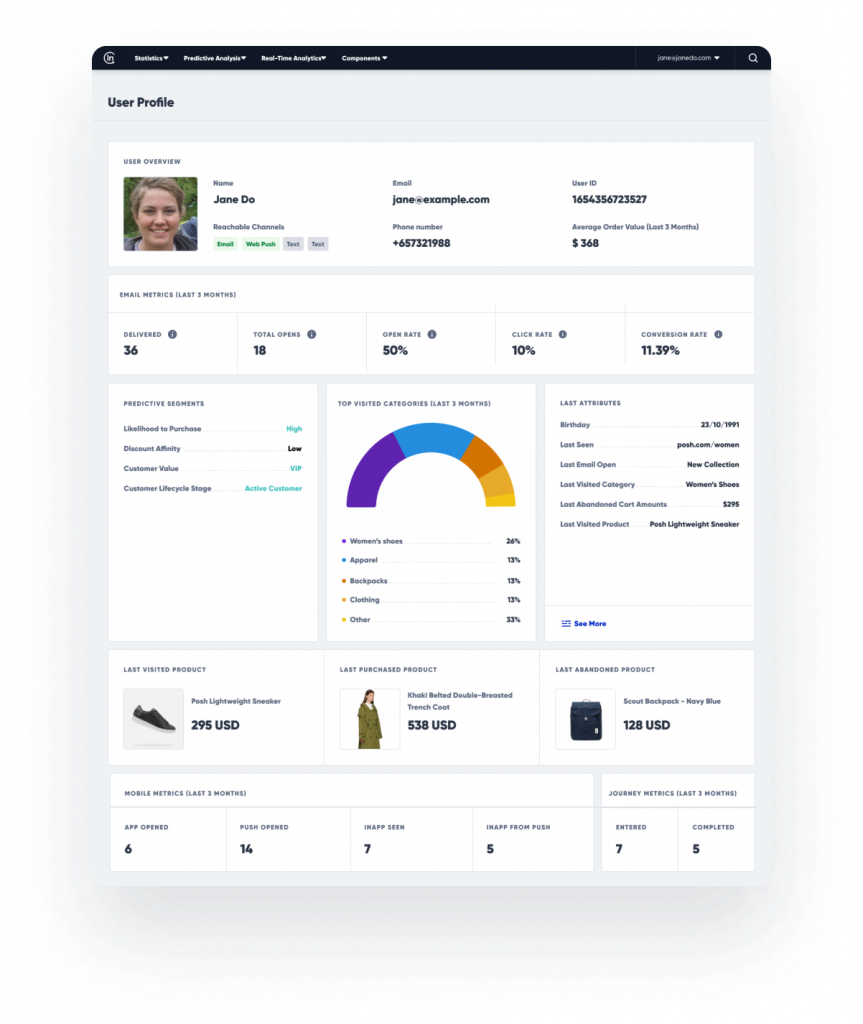
Qu’est-ce que la base de données first-party ?
L’hyperpersonnalisation échoue lorsque le flux d’événements est incomplet ou que le catalogue manque d’attributs nécessaires au classement en fonction des contraintes. Les équipes disposent souvent d’outils d’analyse web mais n’intègrent pas les points de vente (POS), ou disposent de données sur les produits mais n’ont pas de champ de marge.
Votre schéma minimal viable :
Événements obligatoires :
- view_item avec l’ID du produit, la catégorie, le prix
- add_to_cart avec quantité, variante
- achat avec l’ID de la commande, les postes, la remise appliquée
- recherche avec requête, résultats renvoyés
Attributs de catalogue requis :
- UGS, hiérarchie des catégories, prix, niveau de marge, niveau de stock, taux de retour si disponible
Les caractéristiques dérivées valent la peine d’être calculées :
- Les scores de récence, de fréquence et de valeur monétaire (RFM)
- Affinité entre les catégories sur la base du ratio vues/achats
- Affinité à la remise basée sur le taux d’achat avec ou sans code promo
Les équipes dont les capacités d’ingénierie des données sont limitées doivent privilégier l’exhaustivité des événements plutôt que les fonctionnalités dérivées. Un flux d’événements complet avec des attributs de catalogue de base permet de réaliser la plupart des cas d’usage. Si vous souhaitez voir à quoi ressemblent des données et des prises de décision « prêtes pour les contraintes » dans l’ensemble du flux de travail, réservez une démonstration.
Comment fonctionnent la résolution d’identité et le graphe client ?
Le passage en caisse en tant qu’invité crée des profils fragmentés qui gonflent les chiffres de l’audience et rompent la continuité du parcours. Un acheteur qui navigue sur mobile, achète en tant qu’invité sur desktop et retourne en magasin apparaît comme des utilisateurs distincts sans résolution d’identité.
Approches communes de l’appariement :
- Correspondance déterministe : relie les profils lorsque le même identifiant, comme l’email ou le téléphone, apparaît d’une session à l’autre. Confiance élevée, mais nécessite une connexion ou un paiement.
- Correspondance probabiliste : relie les profils en fonction des empreintes digitales de l’appareil ou de la similarité comportementale. Confiance plus faible, utile pour la personnalisation avant l’ouverture de session, mais nécessite un réglage minutieux.
Considérations spécifiques au retail :
- Guest Checkout : Capturez l’email lors du passage à la caisse, même sans création de compte ; il devient la clé de couture pour les visites ultérieures.
- Reçus en magasin : Le scan de fidélité au point de vente permet de relier les achats hors ligne au profil numérique.
- Hachage sécurisé : hacher les identifiants avant de les envoyer à des systèmes tiers ; ne conserver les identifiants bruts que dans la plateforme de données clients (CDP).
Comment fonctionne un moteur de décision en temps réel ?
Les équipes supposent qu’une API de recommandation équivaut à un moteur de décision. Mais une API qui renvoie les produits les mieux classés sans vérifier les plafonds de stock, de marge ou de fréquence fera apparaître les articles en rupture de stock, favorisera les UGS à faible marge auprès des acheteurs à plein tarif et lassera les clients à forte valeur ajoutée.
Le pipeline de décision :
- Récupérer le contexte : Profil de l’utilisateur, événements de la session, métadonnées de la demande
- Scorez les candidats : Appliquez le modèle ML pour classer les produits ou le contenu
- Appliquer des contraintes : Filtrez les éléments qui ne respectent pas les règles de l’entreprise
- Reclassez si nécessaire : Augmentez le nombre d’articles en fonction des priorités de merchandising
- Réponse en retour : Servir la liste finale classée dans le respect de l’accord de niveau de service (ANS) en matière de latence.
Les équipes qui n’ont pas de capacité d’ingénierie ML devraient commencer par des décisions basées sur des règles et ajouter progressivement la notation ML. Un moteur de règles bien réglé est plus performant qu’un modèle mal formé, et vous pouvez vérifier ce que « millisecondes + contraintes » exige réellement dans votre environnement à l’intérieur du hub de démonstration du produit.
Comment fonctionne l’activation omnicanale ?
Un acheteur abandonne son panier sur le web, reçoit un email avec une réduction, clique sur l’application mobile, et voit le prix plein parce que l’offre n’a pas été synchronisée. Cela rompt la confiance et gaspille le budget promotionnel.
Une activation cohérente est nécessaire :
- ID de l’offre/de l’expérience : Chaque expérience personnalisée doit porter un identifiant unique qui persiste à travers les canaux pour l’attribution et pour éviter les rachats en double
- Adaptateurs de canaux : Chaque canal d’activation a besoin d’un adaptateur qui peut recevoir la charge utile de la décision et la restituer de manière appropriée
- Plafonds de fréquence : Appliquer les plafonds au niveau du profil, et non au niveau du canal.
Les médias payants tels que les publicités dynamiques sur les produits devraient puiser dans le même moteur de décision que les canaux détenus afin de maintenir une personnalisation omnicanale
Comment fonctionne le cadre de mesure et d’expérimentation ?
Les équipes signalent que les emails personnalisés ont un taux de clics plus élevé que les emails par lots, mais cela confond le biais de sélection avec l’effet de traitement. Les emails personnalisés sont adressés à des utilisateurs plus engagés. En l’absence de rétention, vous ne pouvez pas prouver que la personnalisation est à l’origine de l’augmentation du taux de clics.
Pour que la mesure soit efficace, il faut
- Retenue globale : Réservez un petit pourcentage du trafic qui ne reçoit aucune personnalisation. Comparez la conversion, la valeur ajoutée et la valeur à long terme entre la réserve et le traitement.
- Tests de maintien au niveau des cas d’usage : Pour chaque nouveau cas d’usage, effectuez un test de maintien avant de passer à l’échelle supérieure. Certains cas d’usage présentent un incrément négatif lorsqu’ils cannibalisent les achats organiques.
- Des indicateurs de performance axés sur la rentabilité : Suivez la marge par commande, et pas seulement le chiffre d’affaires. Une personnalisation qui augmente la conversion en réduisant les clients à marge élevée pour qu’ils achètent des produits à faible marge peut s’avérer négative en termes nets.
Les holdouts réduisent la population recevant la personnalisation, ce qui peut être ressenti comme un manque à gagner à court terme. Mais sans eux, vous optimisez à l’aveugle.
Quels sont les cas d’usage de l’hyperpersonnalisation au retail qui comptent dans le parcours client ?
Les cas d’usage ne sont pas interchangeables. Une équipe disposant de données de catalogue solides mais d’une résolution d’identité faible doit donner la priorité à des cas d’usage différents de ceux d’une équipe disposant d’une identité solide mais de peu d’événements comportementaux.
Comment fonctionnent la recherche personnalisée et la découverte de produits ?
Lorsqu’un acheteur effectue une recherche ou parcourt une page de catégorie, le moteur de décision ajuste le score de pertinence de base en fonction de l’affinité de l’utilisateur, filtre par niveau de stock et augmente les marges si l’utilisateur n’est pas sensible aux remises.
Résultat : les résultats de recherche reflètent les préférences individuelles tout en donnant la priorité aux articles en stock et à forte marge. Mesurez le succès par le taux de conversion des recherches, le revenu par recherche et le taux de résultats nuls.
L’augmentation agressive des marges peut nuire à la perception de la pertinence. Testez avec les entreprises restées sur le carreau avant de passer à l’échelle supérieure.
Comment fonctionnent les modules dynamiques de pages d’accueil et de catégories ?
Chaque emplacement de la page d’accueil est soumis à des règles d’éligibilité. N’affichez un module que si l’utilisateur a consulté cette catégorie récemment. Classez les candidats en fonction de l’engagement prévu, puis filtrez en fonction des plafonds de récurrence afin d’éviter que le même héros ne se répète trop rapidement.
Mesurez grâce au taux de clics sur les modules personnalisés, au taux de rebond et au délai de consultation du premier produit.
Comment gérer les abandons de panier et de navigation avec des offres tenant compte des stocks ?
Lorsqu’un acheteur abandonne son panier ou consulte plusieurs pages de produits sans les ajouter au panier, le moteur de décision vérifie la marge, le niveau de stock et la sensibilité aux remises avant de décider ce qu’il convient d’envoyer.
Si la marge dépasse le seuil et que l’utilisateur est sensible aux remises, incluez une incitation. Si l’utilisateur n’est pas sensible aux remises, envoyez un rappel sans remise. Si le stock est faible, envoyez plutôt un message d’urgence.
Les remises généralisées érodent la marge et incitent les clients à abandonner. Utilisez les scores de sensibilité aux remises pour cibler les incitations uniquement sur les utilisateurs qui en ont besoin, et si vous souhaitez tester votre logique d’abandon par rapport à des contraintes réelles (planchers de marge, stock, plafonds de fréquence), réservez une démo.
Comment fonctionnent le clientélisme en magasin et les recommandations assistées par les associés ?
Lorsqu’un client entre dans un magasin via une application ou un scan de fidélité, faites apparaître les meilleures recommandations basées sur l’affinité en ligne, filtrées par la disponibilité en magasin. Marquez les articles de la liste de souhaits qui sont en stock dans ce magasin.
L’application pour les associés affiche des points de discussion personnalisés. L’application pour les acheteurs affiche des badges « disponible ici ».
La personnalisation en magasin nécessite un consentement explicite et un échange de valeur clair. Les clients qui n’ont pas donné leur accord ne doivent pas recevoir de traitement personnalisé de la part des vendeurs.
Comment fonctionnent les programmes de réapprovisionnement, de reconquête et de fidélisation après achat ?
Lorsque le temps écoulé depuis le dernier achat dépasse le cycle de réapprovisionnement prévu ou que l’utilisateur entre dans un segment à risque de désabonnement, le moteur de décision détermine le message adéquat.
Si la fenêtre de réapprovisionnement est respectée et que le risque de désabonnement est faible, envoyez un rappel sans incitation. Si le risque de désabonnement est élevé, incluez un avantage de fidélité. Si l’utilisateur a renoncé à l’email, utilisez le push ou le service de messages courts (SMS).
Quelles sont les exigences en matière de données et d’IA qui soutiennent l’hyperpersonnalisation sans surveillance ?
L’hyperpersonnalisation nécessite des données comportementales riches, mais la collecte agressive de données érode la confiance et crée un risque de conformité. L’objectif est de disposer d’un minimum de données viables pour une personnalisation maximale.
Comment les retailers doivent-ils structurer la taxonomie des événements et l’ingénierie des fonctionnalités ?
Les fonctionnalités dérivées permettent de débloquer des cas d’usage avancés :
| Fonctionnalité | Dérivation | Case d’usage activé |
| Score d’affinité par catégorie | Ratio vues/achats par catégorie sur une période récente | Reclassement personnalisé des recherches |
| Sensibilité de l’escompte | Taux de conversion avec ou sans promotion | Incitation conditionnelle à l’abandon |
| Score d’intention de session | Profondeur de défilement + temps passé sur la page détaillée du produit (PDP) + ajout au panier en cours de session | Ciblage en temps réel des intentions de sortie |
| Cycle de réapprovisionnement | Nombre médian de jours entre deux achats répétés de la même UGS | Calendrier des rappels après l’achat |
Les caractéristiques dérivées nécessitent un volume d’événements suffisant pour être statistiquement significatives. Pour les catégories à faible trafic, revenez à une logique basée sur des règles.
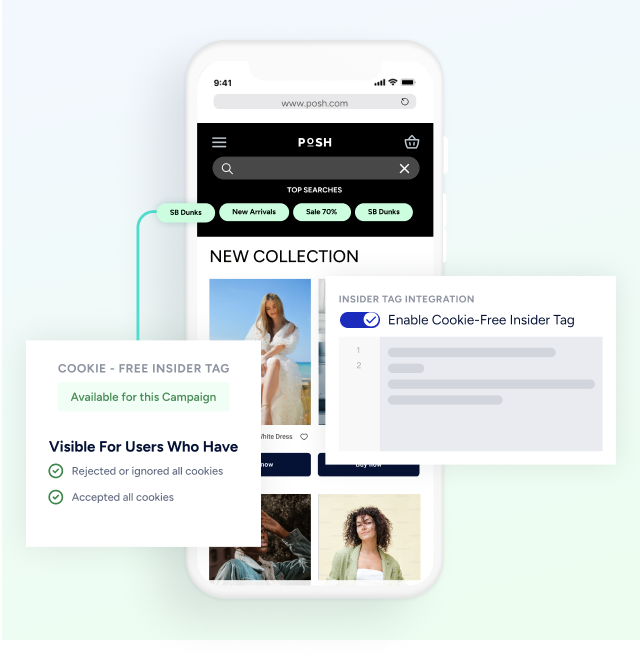
Quels types de modèles devriez-vous utiliser, et quand ?
| Type de modèle | Meilleur pour | Données requises | Limitation |
| Filtrage collaboratif | « Les utilisateurs comme vous ont acheté » | Volume d’achat élevé | Démarrage à froid pour les nouveaux utilisateurs/produits |
| Basé sur le contenu | « Semblable à ce que vous avez vu » | Des attributs de catalogue riches | Ne tient pas compte des préférences inter-catégorielles |
| Modèles de propension | Probabilité d’achat, désabonnement, sensibilité aux remises | Résultats étiquetés | Nécessite une formation continue |
| Les bandits contextuels | Exploration/exploitation en temps réel | Une boucle de feedbacks en direct | Complexité de la mise en œuvre |
Les équipes qui n’ont pas de capacité d’ingénierie ML devraient commencer par une éligibilité basée sur des règles et des algorithmes de recommandation prédéfinis d’un fournisseur.
Comment les équipes doivent-elles gérer le consentement, la protection de la vie privée et l’explicabilité ?
Les gens considèrent la personnalisation comme utile ou intrusive en fonction du sentiment de transparence et de contrôle qu’elle procure.
Faites :
- Saisir le consentement au moment de l’échange de valeurs
- Offrir un centre de préférences où les utilisateurs peuvent ajuster l’intensité de la personnalisation.
- Inclure des explicatifs « Pourquoi est-ce que je vois ça ? » sur le contenu personnalisé.
- Appliquer des plafonds de fréquence au niveau du profil
Ne le faites pas :
- Utiliser des attributs sensibles sans consentement explicite
- Personnalisation basée sur des données que l’utilisateur n’a pas sciemment fournies.
- Montrer une personnalisation qui révèle plus de connaissances que ce à quoi l’utilisateur s’attend.
Le règlement général sur la protection des données (RGPD) et la loi californienne sur la protection de la vie privée des consommateurs (CCPA) exigent le consentement pour la personnalisation dans de nombreux contextes. Intégrez des indicateurs de consentement dans la couche de données afin qu’ils puissent être appliqués au moment de la prise de décision. Si vous souhaitez voir comment les indicateurs de consentement, l’identité et la prise de décision se connectent dans un seul flux de travail, commencez par consulter le hub de démonstration du produit.
Quelle est la feuille de route de l’hyper-personnalisation du retail ?
La plupart des équipes essaient d’instrumenter chaque événement et de construire des modèles personnalisés avant de lancer un seul cas d’usage. Cela retarde la création de valeur et augmente les risques. La feuille de route ci-dessous donne la priorité aux premiers résultats mesurables qui prouvent l’incrémentalité, puis aux échelles.
Comment instrumenter, unifier et diffuser un cas d’usage ?
Commencez par : Mettez en place un suivi des événements de base sur le site web et l’application. Assurez-vous que le flux du catalogue inclut l’ID du produit, la catégorie, le prix, le niveau de stock, le niveau de marge. Configurez la résolution d’identité avec l’email comme clé primaire.
Ensuite, sélectionnez un cas d’utilisation à fort impact : Sélectionnez un cas d’usage à fort impact. La récupération des paniers abandonnés est le point de départ le plus courant, car il comporte des déclencheurs clairs et des résultats mesurables. Construisez une logique de décision avec des contraintes de base. Créez un groupe d’attente.
Ensuite : Exécutez le cas d’usage suffisamment longtemps pour obtenir des résultats stables. Comparez le traitement par rapport à l’abstention sur le taux de conversion, le chiffre d’affaires annuel et la marge par commande. Documentez les enseignements tirés et affinez les règles d’éligibilité.
Critères de sortie : Un cas d’usage en direct avec maintien, une levée incrémentale positive mesurée, un flux d’événements validé.
Comment étendre les cas d’usage, ajouter des canaux et formaliser les tests ?
Ajoutez des cas d’usage supplémentaires comme la recherche personnalisée, les modules de page d’accueil ou le réapprovisionnement après achat. Chaque nouveau cas d’usage fait l’objet d’un test de résistance avant d’être mis à l’échelle.
Étendez l’activation à d’autres canaux tels que les SMS, le push et les médias payants. Veillez à ce que les identifiants de l’offre soient conservés sur tous les canaux pour l’attribution.
Établissez une réserve globale pour mesurer l’impact cumulatif. Créez un calendrier d’essais avec des responsables clairement identifiés.
Critères de sortie : Plusieurs cas d’usage sont en cours avec une augmentation progressive positive, une retenue globale est en place, l’activation transcanal est fonctionnelle.
Comment automatiser, gouverner et optimiser ?
Mettez en œuvre la sélection automatique des gagnants pour les A/B tests. Activez la logique du Next Best Channel. Ajoutez une notation basée sur le ML pour les caractéristiques de propension et d’affinité.
Établir une fréquence d’examen des performances du modèle. Définissez des budgets de coûts et de latence. Créez des flux de travail d’exception pour les cas particuliers tels que les clients VIP ou les mises en attente de conformité.
Critères de sortie : Prise de décision automatisée pour de multiples cas d’usage, cadence de gouvernance établie, amélioration progressive et durable par rapport à un maintien global.
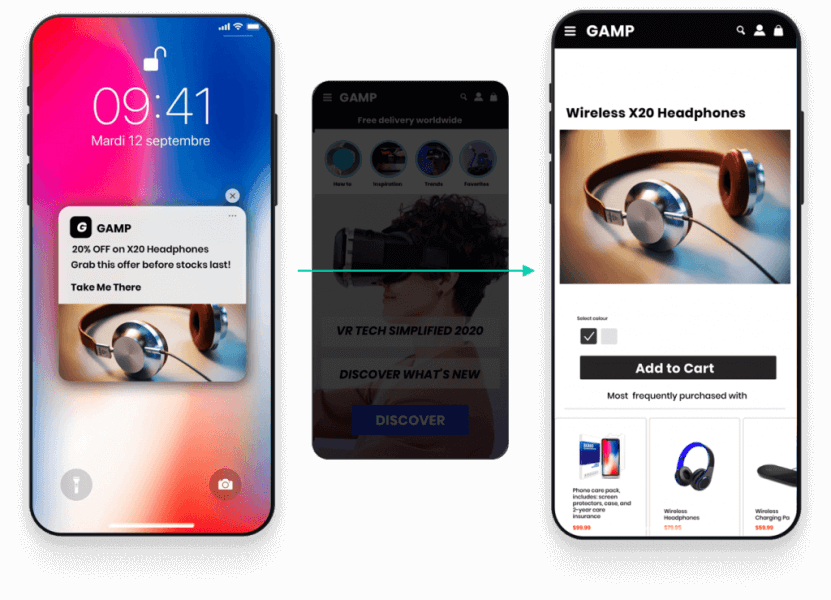
Comment Insider One favorise-t-il l’hyperpersonnalisation du retail ?
Nous réunissons les composants décrits ci-dessus au sein d’une plateforme unique, éliminant ainsi la complexité d’intégration qui ralentit la plupart des initiatives d’hyperpersonnalisation.
Données unifiées sur les clients : Notre CDP unifie les données comportementales, transactionnelles et de catalogue dans des profils complets avec une résolution d’identité configurable. Les équipes sont rapidement opérationnelles, Migration Lab™ se chargeant de l’onboarding zéro friction à partir des systèmes existants.
Prise de décision en temps réel avec Insider One AI: Insider One AI, le vaste ensemble de capacités d’IA d’Insider One, alimente des segments prédictifs pour la probabilité d’achat, le désabonnement et l’affinité avec les remises. Smart Recommender délivre des recommandations de produits personnalisées grâce à un large ensemble d’algorithmes avec gestion des contraintes. La sélection automatique A/B optimise automatiquement les variantes.
Activation omnicanale avec Architect : Architect, la solution d’ orchestration des parcours clients d’Insider One, permet aux équipes de construire des parcours cross-canal sur un canevas unique avec une prise en charge native de l’email, du SMS, de WhatsApp, du web push, de l’app push et des médias payants. La logique Next Best Channel sélectionne le point de contact optimal par utilisateur.
Mesure intégrée : L’ analyse comportementale ferme la boucle entre l’exécution de la campagne et la connaissance, avec l’analyse de l’entonnoir, du flux et de la cohorte disponible sans outil de BI séparé.
Si vous voulez vraiment passer de « nous avons des données » à « nous prenons des décisions lucratives en temps réel », demandez une démo et faites correspondre votre premier cas d’usage à la pile qui peut réellement le lancer.
FAQ
La personnalisation basée sur les segments regroupe les clients en fonction de traits communs et leur fait vivre la même expérience. L’hyperpersonnalisation prend des décisions au niveau individuel, en temps réel, en utilisant des signaux comportementaux en direct et des contraintes commerciales telles que les stocks et les marges. La différence déterminante est la prise de décision par demande par rapport aux listes d’audience préétablies.
Au minimum, vous avez besoin d’événements comportementaux tels que la consultation de produits, l’ajout au panier, les achats et les recherches, ainsi que d’attributs de catalogue tels que le prix, la catégorie, le niveau de stock et l’échelon de marge. La résolution de l’identité qui suture les profils à travers les sessions et les canaux est nécessaire pour assurer la continuité du parcours. L’UCD d’Insider One ingère tous ces éléments en mode natif, y compris les événements hors ligne via l’API Upsert.
Les équipes peuvent lancer un premier cas d’usage avec une augmentation mesurable en l’espace d’un trimestre en se concentrant sur un schéma d’événement minimal, un cas d’usage initial à fort impact tel que l’abandon de panier, et un groupe d’attente pour isoler les effets du traitement. L’assistant d’intégration Web SDK 2.0 et le laboratoire de migration d’Insider One sont conçus pour réduire la phase de préparation des données qui prend généralement le plus de temps dans les implémentations concurrentes.
Utilisez des groupes de retenus pour comparer le taux de conversion, l’AOV et la marge par commande entre les utilisateurs qui bénéficient d’expériences personnalisées et ceux qui n’en bénéficient pas. Cela permet d’isoler le véritable impact différentiel du biais de sélection. Le groupe de contrôle Architect d’Insider One (bêta privée) permet de le faire au niveau de l’ensemble du programme, et pas seulement au niveau des campagnes individuelles.
Intégrez le consentement dans la couche de données afin que les drapeaux soient appliqués au moment de la prise de décision. Proposez un centre de préférences où les utilisateurs peuvent contrôler l’intensité de la personnalisation. Incluez des explications sur la raison pour laquelle je vois ceci dans le contenu personnalisé. Évitez d’utiliser des attributs sensibles ou déduits sans autorisation explicite. Ne personnalisez jamais sur la base de données que l’utilisateur n’a pas sciemment fournies.
L’Architect d’Insider One prend en charge l’email, le SMS, WhatsApp (y compris les modèles transactionnels et marketing, l’AI Shopping Agent et les flux conversationnels bidirectionnels), le web push, l’app push, la messagerie in-app, RCS (en bêta), TikTok (en cours de réalisation), les médias payants et en magasin via l’intégration d’événements hors ligne. Tous les canaux sont orchestrés à partir d’un canevas unique avec des plafonds de fréquence, des identifiants d’offre et une attribution partagés.
La suite Agent One d’Insider One comprend un agent IA Instagram en direct qui convertit les clics publicitaires en conversations d’achat in-app, un agent d’achat IA WhatsApp en direct alimenté par le catalogue de produits Insider One, et un serveur MCP Insider qui permet aux systèmes IA d’interagir avec les analyses de la plateforme avec précision et gouvernance. En cours de développement : Personnalisation d’agent IA pilotée par UCD, Widgets d’agent IA, orchestration de parcours client pilotée par agent, agent vocal IA avec prise en charge humaine, et une suite d’évaluation d’agent IA pour une mesure continue de la qualité.

Continuer à lire
10 min.
Muharrem Derinkok
11 Oct 2024
20 min.
Chris Baldwin
22 Juil 2026
25 min.
Chris Baldwin
22 Juil 2026